
L'utilitaire wget télécharge des pages Web, des fichiers et des images à partir du Web à l'aide de la ligne de commande Linux. Vous pouvez utiliser une seule commande wget pour télécharger à partir d'un site ou configurer un fichier d'entrée pour télécharger plusieurs fichiers sur plusieurs sites. Selon la page de manuel, wget peut être utilisé même lorsque l'utilisateur s'est déconnecté du système. Pour ce faire, utilisez la commande nohup.
Caractéristiques de la commande wget
Vous pouvez télécharger des sites Web entiers en utilisant wget, et convertissez les liens pour qu'ils pointent vers des sources locales afin que vous puissiez afficher un site Web hors ligne. L'utilitaire wget tente également un téléchargement lorsque la connexion tombe et reprend là où elle s'était arrêtée, si possible, lorsque la connexion revient.
Les autres fonctionnalités de wget sont les suivantes:
- Téléchargez des fichiers via HTTP, HTTPS et FTP.
- Reprenez les téléchargements.
- Convertissez les liens absolus dans les pages Web téléchargées en URL relatives afin que les sites Web puissent être consultés hors ligne.
- Prend en charge les proxy et cookies HTTP.
- Prend en charge les connexions HTTP persistantes.
- Peut fonctionner en arrière-plan même lorsque vous n'êtes pas connecté.
- Fonctionne sous Linux et Windows.
Comment télécharger un site Web à l'aide de wget
Pour ce guide, vous apprendrez à télécharger ce blog Linux:
wget www.ever
Avant de commencer, créez un dossier sur votre ordinateur à l'aide de la commande mkdir, puis déplacez-vous dans le dossier à l'aide de la commande cd.
Exemple :
mkdir tous les jourslinuxuser
cd tous les jours
wget www.ever
Le résultat est un fichier index.html unique contenant le contenu extrait de Google. Les images et les feuilles de style sont conservées sur Google.
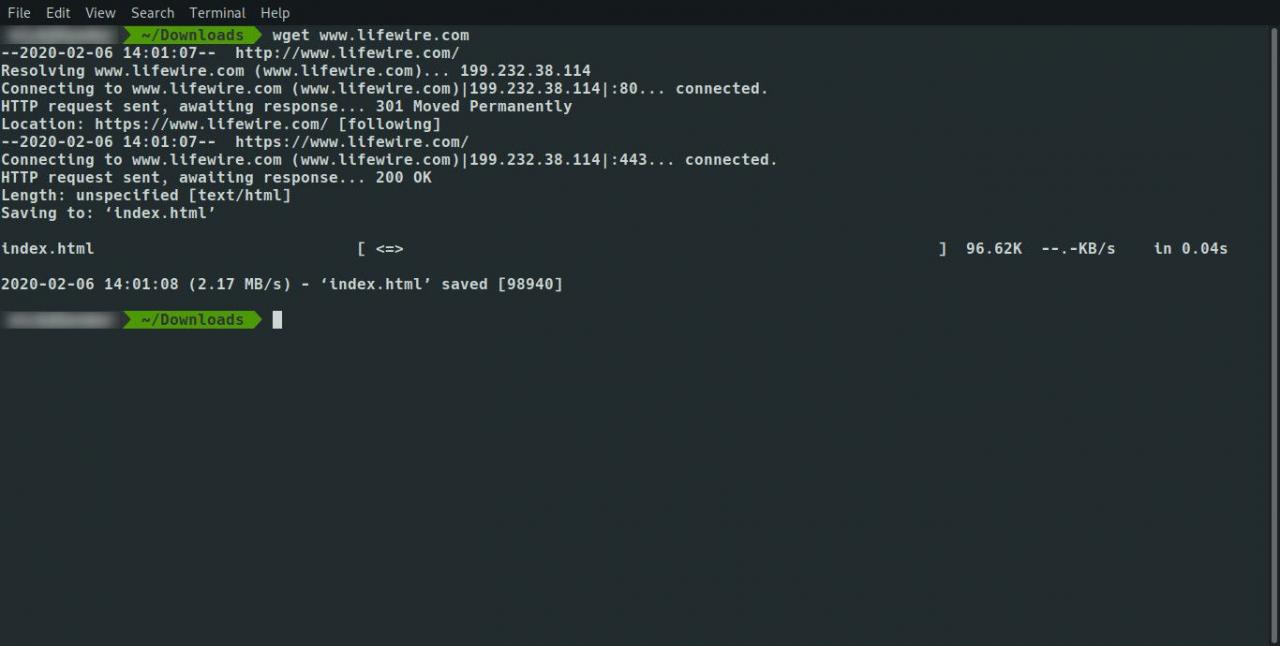
Pour télécharger le site complet et toutes les pages, utilisez la commande suivante:
wget -r www.ever
Cela télécharge les pages de manière récursive jusqu'à un maximum de 5 niveaux de profondeur. Cinq niveaux de profondeur pourraient ne pas suffire pour tout obtenir du site. Utilisez le -l pour définir le nombre de niveaux auxquels vous souhaitez accéder, comme suit:
wget -r -l10 www.ever
Si vous voulez une récursion infinie, utilisez ce qui suit:
wget -r -l inf www.ever
Vous pouvez également remplacer le inf avec 0, ce qui signifie la même chose.
Il y a encore un problème. Vous pouvez obtenir toutes les pages localement, mais les liens dans les pages pointent vers l'emplacement d'origine. Il n'est pas possible de cliquer localement entre les liens sur les pages.
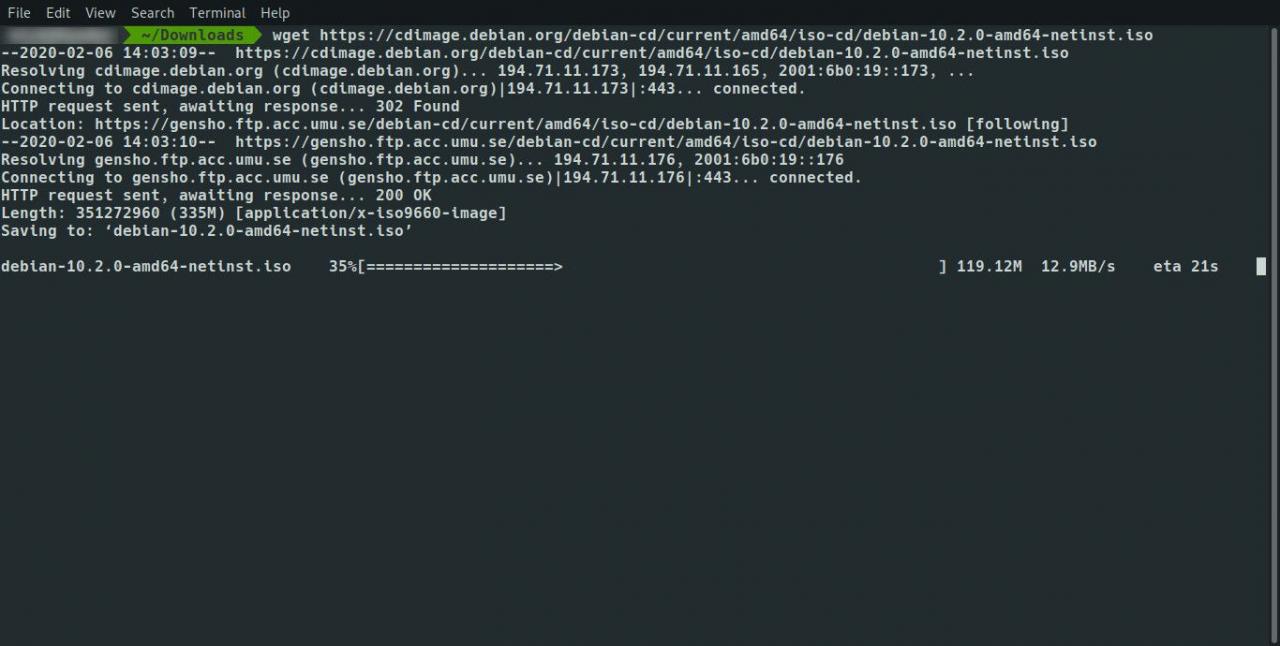
Pour contourner ce problème, utilisez le -k commutateur pour convertir les liens sur les pages pour pointer vers l'équivalent téléchargé localement, comme suit:
wget -r -k www.ever
Si vous souhaitez obtenir un miroir complet d'un site Web, utilisez le commutateur suivant, ce qui élimine la nécessité d'utiliser le -r, -k -l interrupteurs.
wget -m www.ever
Si vous avez un site Web, vous pouvez effectuer une sauvegarde complète en utilisant cette simple commande.
Exécutez wget en tant que commande d'arrière-plan
Vous pouvez exécuter wget en tant que commande d'arrière-plan, vous permettant de continuer votre travail dans la fenêtre du terminal pendant le téléchargement des fichiers. Utilisez la commande suivante:
wget -b www.ever
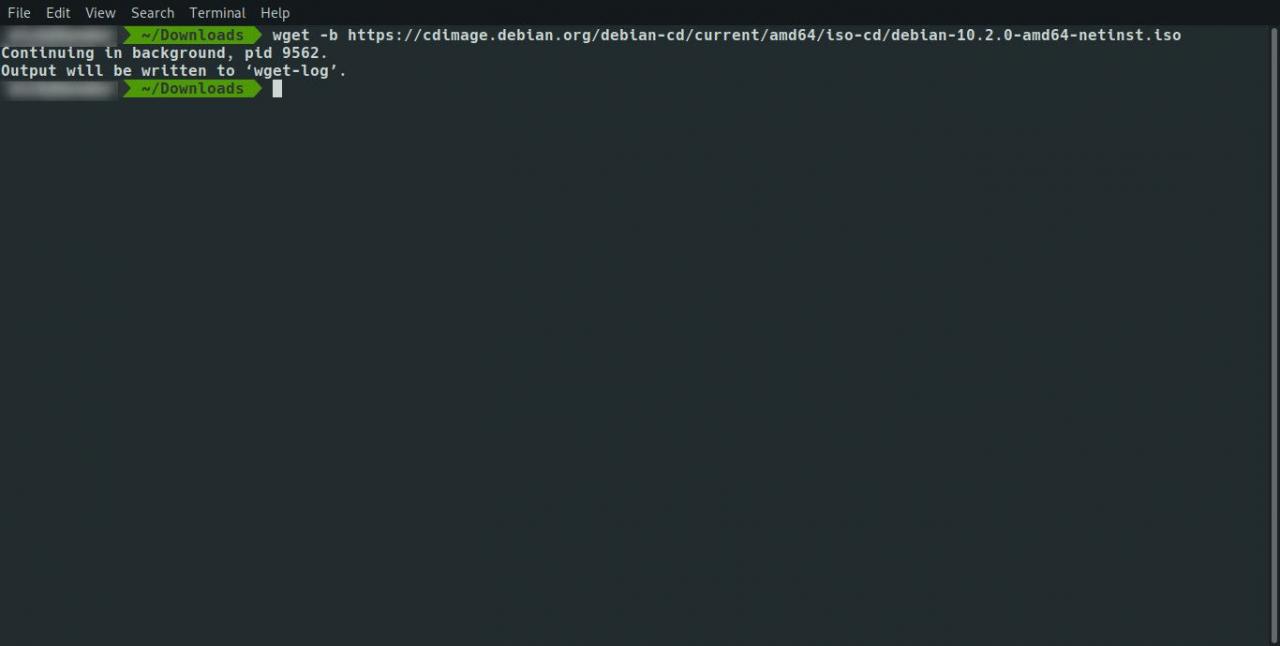
Vous pouvez combiner des commutateurs. Pour exécuter la commande wget en arrière-plan lors de la mise en miroir du site, utilisez la commande suivante:
wget -b -m www.ever
Vous pouvez simplifier cela davantage, comme suit:
wget -bm www.ever
Journal
Si vous exécutez la commande wget en arrière-plan, vous ne voyez aucun des messages normaux qu'elle envoie à l'écran. Pour envoyer ces messages à un fichier journal afin de pouvoir vérifier la progression à tout moment, utilisez la commande tail.
Pour afficher les informations de la commande wget dans un fichier journal, utilisez la commande suivante:
wget -o / chemin / vers / mylogfile www.ever
L'inverse est de ne nécessiter aucune journalisation et aucune sortie à l'écran. Pour omettre toutes les sorties, utilisez la commande suivante:
wget -q www.ever
Télécharger à partir de plusieurs sites
Vous pouvez configurer un fichier d'entrée à télécharger à partir de nombreux sites différents. Ouvrez un fichier à l'aide de votre éditeur préféré ou de la commande cat et répertoriez les sites ou les liens à télécharger sur chaque ligne du fichier. Enregistrez le fichier, puis exécutez la commande wget suivante:
wget -i /
En plus de sauvegarder votre site Web ou de trouver quelque chose à télécharger pour le lire hors ligne, il est peu probable que vous souhaitiez télécharger un site Web entier. Vous êtes plus susceptible de télécharger une seule URL avec des images ou de télécharger des fichiers tels que des fichiers zip, des fichiers ISO ou des fichiers image.
Dans cet esprit, vous n'avez pas à taper ce qui suit dans le fichier d'entrée car cela prend du temps:
- http://www.myfileserver.com/file1.zip
- http://www.myfileserver.com/file2.zip
- http://www.myfileserver.com/file3.zip
Si vous savez que l'URL de base est la même, spécifiez ce qui suit dans le fichier d'entrée:
- file1.zip
- file2.zip
- file3.zip
Vous pouvez ensuite fournir l'URL de base dans le cadre de la commande wget, comme suit:
wget -B http://www.myfileserver.com -i /
Options de nouvelle tentative
Si vous configurez une file d'attente de fichiers à télécharger dans un fichier d'entrée et que vous laissez votre ordinateur en marche pour télécharger les fichiers, le fichier d'entrée peut rester bloqué pendant votre absence et réessayer de télécharger le contenu. Vous pouvez spécifier le nombre de tentatives à l'aide du commutateur suivant:
wget -t 10 -i /
Utilisez la commande ci-dessus en conjonction avec le -T commutateur pour spécifier un délai en secondes, comme suit:
wget -t 10 -T 10 -i /
La commande ci-dessus réessaiera 10 fois et se connectera pendant 10 secondes pour chaque lien dans le fichier.
C'est également gênant lorsque vous téléchargez 75% d'un fichier de 4 Go sur une connexion haut débit lente uniquement pour que la connexion soit interrompue. Pour utiliser wget pour réessayer à partir de l'endroit où il a arrêté le téléchargement, utilisez la commande suivante:
wget -c www.myfileser
Si vous martelez un serveur, l'hôte pourrait ne pas l'aimer et bloquer ou tuer vos requêtes. Vous pouvez spécifier une période d'attente pour spécifier la durée d'attente entre chaque extraction, comme suit:
wget -w 60 -i /
La commande ci-dessus attend 60 secondes entre chaque téléchargement. Ceci est utile si vous téléchargez de nombreux fichiers à partir d'une seule source.
Certains hébergeurs peuvent repérer la fréquence et vous bloquer. Vous pouvez rendre la période d'attente aléatoire pour donner l'impression que vous n'utilisez pas de programme, comme suit:
wget - attente-aléatoire -i /
Protéger les limites de téléchargement
De nombreux fournisseurs de services Internet appliquent des limites de téléchargement pour l'utilisation du haut débit, en particulier pour ceux qui vivent en dehors d'une ville. Vous pouvez ajouter un quota afin de ne pas dépasser votre limite de téléchargement. Vous pouvez le faire de la manière suivante:
wget -q 100m -i /
Le système -q La commande ne fonctionnera pas avec un seul fichier. Si vous téléchargez un fichier d'une taille de 2 gigaoctets, utilisez -q 1000m n'empêche pas le téléchargement du fichier.
Le quota n'est appliqué que lors d'un téléchargement récursif depuis un site ou lors de l'utilisation d'un fichier d'entrée.
Traversez la sécurité
Certains sites exigent que vous vous connectiez pour accéder au contenu que vous souhaitez télécharger. Utilisez les commutateurs suivants pour spécifier le nom d'utilisateur et le mot de passe.
wget --user = votre nom d'utilisateur - mot de passe
Sur un système multi-utilisateurs, lorsqu'un utilisateur exécute le ps commande, ils peuvent voir votre nom d'utilisateur et votre mot de passe.
Autres options de téléchargement
Par défaut, le -r switch télécharge récursivement le contenu et crée des répertoires au fur et à mesure. Pour obtenir tous les fichiers à télécharger dans un seul dossier, utilisez le commutateur suivant:
Le contraire est de forcer la création de répertoires qui peut être réalisée à l'aide de la commande suivante:
Comment télécharger certains types de fichiers
Si vous souhaitez télécharger de manière récursive à partir d'un site, mais que vous souhaitez uniquement télécharger un type de fichier spécifique tel qu'un MP3 ou une image telle qu'un PNG, utilisez la syntaxe suivante:
wget -A &
L'inverse est d'ignorer certains fichiers. Vous ne souhaitez peut-être pas télécharger les exécutables. Dans ce cas, utilisez la syntaxe suivante:
wget -R &
Cliget
Il existe un add-on Firefox appelé cliget. Pour ajouter ceci à Firefox:
-
Visitez https://addons.mozilla.org/en-US/firefox/addon/cliget/ et cliquez sur le ajouter à Firefox .
-
Cliquez installer bouton quand il apparaît, puis redémarrez Firefox.
-
Pour utiliser cliget, visitez une page ou un fichier que vous souhaitez télécharger et faites un clic droit. Un menu contextuel apparaît appelé cliget, et il existe des options pour copier wget et copier pour boucler.
-
Cliquez copier vers wget option, ouvrez une fenêtre de terminal, puis cliquez avec le bouton droit de la souris et choisissez paste. La commande wget appropriée est collée dans la fenêtre.
Cela vous évite d'avoir à taper la commande vous-même.
Résumé
La commande wget a un certain nombre d'options et de commutateurs. Pour lire la page de manuel de wget, tapez ce qui suit dans une fenêtre de terminal:
homme wget
#goog-gt-tt {display:none !important;}.goog-te-banner-frame {display:none !important;}.goog-te-menu-value:hover {text-decoration:none !important;}body {top:0 !important;}#gtranslate_element {display:none!important;}
var gt_not_translated_list = ["wget www.ever","wget -r www.ever","wget -r -l10 www.ever","wget -r -l inf www.ever","wget -m www.ever","wget -b www.ever","wget -b -m www.ever","wget -bm www.ever","wget -q www.ever","wget -i /","wget -B http://www.myfileserver.com -i /","wget -c www.myfileser","wget -w 60 -i /","wget -q 100m -i /","Cliget"];
document.cookie = "googtrans=/auto/fr; domain=.balogs.xyz";
document.cookie = "googtrans=/auto/fr";
function GTranslateElementInit() {new google.translate.TranslateElement({pageLanguage: 'auto',layout: google.translate.TranslateElement.InlineLayout.SIMPLE,autoDisplay: false,multilanguagePage: true}, 'gtranslate_element');}